Using Rubin OpSims in Simulations
A critical aspect to producing realistic simulations of time varying phenomena is correctly modeling the cadence at which the objects will be observed and capturing the relevant physical details about the observation. LightCurveLynx provides an OpSim module that can load a Rubin opsim file and use that to filter observations based on location, associate observations with their filter, apply detector noise, etc. OpSim objects are subclasses of the more general ObsTable data structures
and a lot of the same concepts apply to ObsTables for different surveys.
NOTE: This notebook provides an introduction to using opsim data in the simulations. Actual observations from LSSTCam are provided in a different format and should be loaded using the LSSTObsTable class. For an example of how to load a CCD Visit table from actual runs, such as DP1, see the corresponding notebook.
OpSim Class
The OpSim object provides a wrapper for loading and querying simulated Rubin survey data, including pointings and survey information. The required information is:
the pointing data (RA, dec, and times for each pointing), and
the zero point information for each pointing (a zero point column or the information needed to derive it)
Other common information includes the airmass, exposure time, and filter used (the information needed to derive the zero points).
Internally, the OpSim objects use a table with the column names are given by the imported data. For Rubin opsim files, this means columns will have names such as “observationStartMJD” or “fieldRA”. Since different inputs may have different columns, the class provides the ability to map simple column names such as “ra” and “time” to the corresponding table names. The constructor allows the user to pass a column-mapping dictionary that maps the short column name to the name used within the
database. The default column-mapper corresponds to the Rubin opsim format:
“airmass” -> “airmass”
“dec” -> “fieldDec”
“exptime” -> “visitExposureTime”
“filter” -> “filter”
“ra” -> “fieldRA”
“time” -> “observationStartMJD” By default
OpSimwill look for Rubin column names, such as “observationStartMJD” and “fieldRA”.
We can create a simple OpSim by manually specifying the data as a dict or a pandas dataframe.
[1]:
import numpy as np
from lightcurvelynx.obstable.opsim import OpSim
input_data = {
"observationStartMJD": np.array([0.0, 1.0, 2.0, 3.0, 4.0]),
"fieldRA": np.array([15.0, 30.0, 15.0, 0.0, 60.0]),
"fieldDec": np.array([-10.0, -5.0, 0.0, 5.0, 10.0]),
"zp_nJy": np.ones(5),
}
ops_data = OpSim(input_data)
print(ops_data._table)
time ra dec zp
0 0.0 15.0 -10.0 1.0
1 1.0 30.0 -5.0 1.0
2 2.0 15.0 0.0 1.0
3 3.0 0.0 5.0 1.0
4 4.0 60.0 10.0 1.0
/home/docs/checkouts/readthedocs.org/user_builds/lightcurvelynx/envs/stable/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Once we have an OpSim object, we can use the [] notation to access data directly. OpSim has the same mechanics as a pandas data frame. The columns are named and correspond to input attributes. Each row provides the information for a single pointing.
As noted above, the column mapping allows us to access column by either their given name (“observationStartMJD”) or their shortened name (“time”).
[2]:
ops_data["observationStartMJD"] # Same as ops_data["time"]
[2]:
0 0.0
1 1.0
2 2.0
3 3.0
4 4.0
Name: time, dtype: float64
Loading an OpSim
Most users will want to load a pre-existing OpSim from a database file using the from_db(), from_url(), or from_parquet() functions. The from_url() function will download the opsim db from a given URL to LightCurveLynx’s data cache (if needed) and load the opsim from the db file. For Rubin, a large number of OpSims can be found at https://s3df.slac.stanford.edu/data/rubin/sim-data/. For many studies you will want the most recent version of a baseline survey. But some users
might want older versions or alternate approaches.
[3]:
opsim_url = "https://s3df.slac.stanford.edu/data/rubin/sim-data/sims_featureScheduler_runs5.3/baseline/baseline_v5.3.0_10yrs.db"
# Uncomment the following line to load data from a URL
# ops_data = OpSim.from_url(opsim_url)
If the file has already been downloaded, the code will not redownload it unless the user sets force_download=True.
Alternatively if you are using a local OpSim with a known file path, you can use from_db() or from_parquet() to read it directly.
[4]:
opsim_file = "../../tests/lightcurvelynx/data/opsim_shorten.db"
ops_data = OpSim.from_db(opsim_file)
print(f"Loaded an opsim database with {len(ops_data)} entries.")
print(f"Columns: {ops_data.columns}")
Loaded an opsim database with 100 entries.
Columns: Index(['observationId', 'ra', 'dec', 'time', 'flush_by_mjd', 'exptime', 'band',
'filter', 'rotation', 'rotSkyPos_desired', 'nexposure', 'airmass',
'seeingFwhm500', 'seeing', 'seeingFwhmGeom', 'skybrightness', 'night',
'slewTime', 'visitTime', 'slewDistance', 'maglim', 'altitude',
'azimuth', 'paraAngle', 'pseudoParaAngle', 'cloud', 'moonAlt', 'sunAlt',
'scheduler_note', 'target_name', 'target_id', 'observationStartLST',
'rotTelPos', 'rotTelPos_backup', 'moonAz', 'sunAz', 'sunRA', 'sunDec',
'moonRA', 'moonDec', 'moonDistance', 'solarElong', 'moonPhase',
'cummTelAz', 'observation_reason', 'science_program',
'cloud_extinction', 'zp', 'psf_footprint', 'sky_bg_e'],
dtype='str')
We can create a Multi-Order Coverage Map (MOC) of the area covered by the OpSim (or any ObsTable)
[5]:
moc = ops_data.build_moc()
We can also plot the survey’s coverage on the sky.
[6]:
ops_data.plot_footprint()
[6]:
(<Figure size 640x480 with 1 Axes>, <WCSAxes: >)
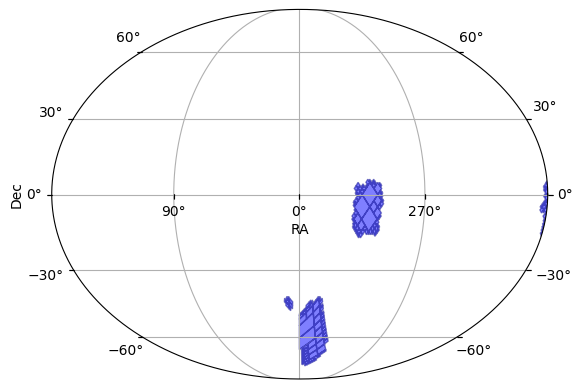
Spatial Matching
OpSim provides a framework for efficiently determining when an object was observed given its (RA, Dec). We use the range_search() function to retrieve all pointings within a given radius of the query point.
We start by taking the (RA, Dec) of the first observation in the table and using that to determine all times this position was observed.
[7]:
query_ra = ops_data["ra"][0]
query_dec = ops_data["dec"][0]
print(f"Searching for ({query_ra}, {query_dec}).")
# Find everything within 0.5 degrees of the query point.
matches = ops_data.range_search(query_ra, query_dec, radius=0.5)
print(f"Found {len(matches)} matches at {matches}")
Searching for (9.201843801237983, -44.06832623982988).
Found 2 matches at [0, 1]
/home/docs/checkouts/readthedocs.org/user_builds/lightcurvelynx/envs/stable/lib/python3.12/site-packages/lightcurvelynx/obstable/obs_table.py:820: UserWarning: Provided radius 0.5 is smaller than the ObsTable radius 1.75. This may lead to unexpected results if a detector footprint is used.
warnings.warn(
Once we have the indices, we can use those to find the other information about the pointings.
[8]:
ops_data["time"][matches]
[8]:
0 61213.422046
1 61213.422455
Name: time, dtype: float64
We can run the spatial search in batch mode by providing a lists of RA and Dec. The range_search() will return a list of numpy arrays where each element in the top-level list represents the matches for a single query (RA, Dec).
[9]:
num_queries = 10
query_ra = ops_data["ra"][0:num_queries]
query_dec = ops_data["dec"][0:num_queries]
matches = ops_data.range_search(query_ra, query_dec, radius=0.5)
for idx, m_ids in enumerate(matches):
print(f"{idx}: ({query_ra[idx]}, {query_dec[idx]}) matched {m_ids}")
0: (9.201843801237983, -44.06832623982988) matched [0, 1]
1: (9.314750266540228, -43.87806037204318) matched [0, 1]
2: (315.854437314087, -14.257998568262733) matched [2]
3: (318.18053901082004, -12.486949410932953) matched [3, 21]
4: (315.54816323552814, -11.087801902694105) matched [4]
5: (317.9077003590246, -9.29759017697126) matched [5]
6: (315.3633238085173, -7.908779514470671) matched [6]
7: (317.77499691646034, -6.106225156897575) matched [7, 24]
8: (315.2860541451764, -4.734782764002771) matched [8]
9: (312.7952555040901, -3.370109660163568) matched [9]
Applying Noise
Users can apply different noise models that use information from the OpSim. By default the OpSim will use a PoissonFluxNoiseModel. These noise models take the predicted fluxes for a subset of observations (bandflux of the point source in nJy), the ObsTable, and the corresponding row indices of those observations (in the ObsTable). It returns the simulated bandflux noise in nJy and the modified observations.
[10]:
from lightcurvelynx.noise_models.base_noise_models import PoissonFluxNoiseModel
fluxes = np.array([100.0, 200.0, 300.0])
noise_model = PoissonFluxNoiseModel()
noisy_fluxes, flux_errors = noise_model.apply_noise(
fluxes,
obs_table=ops_data,
indices=np.array([0, 1, 2]),
rng=np.random.default_rng(42),
)
print("Noisy fluxes:", noisy_fluxes)
print("Flux errors:", flux_errors)
Noisy fluxes: [124.64296154 115.78215191 362.2127252 ]
Flux errors: [80.8716123 80.97993766 82.90042783]
Filtering
Depending on the analysis we run, we might want to use only a subset of the data. OpSim provides a helper function filter_rows() that can be used to filter the data in an OpSim and thus speed up subsequent operations. This function creates a new copy of the data set with a subset of the rows.
[11]:
input_data["filter"] = np.array(["r", "g", "g", "r", "g"])
ops_data2 = OpSim(input_data)
print("BEFORE:")
print(ops_data2._table)
ops_data3 = ops_data2.filter_rows(ops_data2["filter"] == "g")
print("\n\nAFTER:")
print(ops_data3._table)
BEFORE:
time ra dec zp filter
0 0.0 15.0 -10.0 1.0 r
1 1.0 30.0 -5.0 1.0 g
2 2.0 15.0 0.0 1.0 g
3 3.0 0.0 5.0 1.0 r
4 4.0 60.0 10.0 1.0 g
AFTER:
time ra dec zp filter
0 1.0 30.0 -5.0 1.0 g
1 2.0 15.0 0.0 1.0 g
2 4.0 60.0 10.0 1.0 g
In addition to filtering the rows in the table, the function will also update the cached data structures within the OpSim object, such as the KD-tree.
Scalability and Testing
To test the scalability of the OpSim we can user the create_random_opsim() helper function to generate completely random data by sampling uniformly over the surface of a sphere. This will not be a realistic survey since it will cover both the Northern and Southern hemisphere, but can provide a good test set for timing.
[12]:
from lightcurvelynx.obstable.opsim import create_random_opsim
# Create an opsim with 1,000,000 observations.
num_obs = 1_000_000
opsim_data2 = create_random_opsim(num_obs)
# Use the first 10,000 samples as queries.
num_queries = 100_000
query_ra = np.asarray(opsim_data2["ra"][0:num_queries])
query_dec = np.asarray(opsim_data2["dec"][0:num_queries])
Using the large OpSim data, we can test where batching speeds up the range search.
[13]:
%%timeit
for i in range(num_queries):
_ = opsim_data2.range_search(query_ra[i], query_dec[i], radius=0.5)
/home/docs/checkouts/readthedocs.org/user_builds/lightcurvelynx/envs/stable/lib/python3.12/site-packages/lightcurvelynx/obstable/obs_table.py:820: UserWarning: Provided radius 0.5 is smaller than the ObsTable radius 1.75. This may lead to unexpected results if a detector footprint is used.
warnings.warn(
4.5 s ± 12.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
[14]:
%%timeit
_ = opsim_data2.range_search(query_ra, query_dec, radius=0.5)
531 ms ± 4.06 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Sampling
We can sample RA, Dec, and time from an OpSim object using the ObsTableRADECSampler node. This will select a random observation from the OpSim and then create a random (RA, Dec) from near the center of that observation.
This allows us to generate fake query locations for testing that are compatible with arbitrary OpSims as opposed to generating a large number of fake locations and then filtering only those that match the opsim. The distribution will be weighted by the opsim’s pointing. If it points at region A 90% of time time and region B 10% of the time, then 90% of the resulting points will be from region A and 10% from region B.
[15]:
from lightcurvelynx.math_nodes.ra_dec_sampler import ObsTableRADECSampler
sampler_node = ObsTableRADECSampler(ops_data)
# Test we can generate a single value.
(ra, dec, time) = sampler_node.generate(num_samples=10)
for i in range(10):
print(f"{i}: ({ra[i]}, {dec[i]}) at t={time[i]}")
0: (317.6885894221345, -1.476730186174153) at t=61214.319904316166
1: (342.58262174446634, -43.49732481147069) at t=61208.44489184432
2: (342.15688798123085, -59.24770329031978) at t=61208.43670152503
3: (312.93771185390307, -11.926304299170734) at t=61214.3137202128
4: (338.36539210468266, -71.66147838609689) at t=61208.43498354902
5: (314.1980387873204, -7.074789599414694) at t=61214.31769400193
6: (314.8004012701717, -4.482374468877589) at t=61214.3100929507
7: (307.1269989085469, -10.584796843923874) at t=61214.31144476043
8: (312.6584802534229, 0.8946696170144254) at t=61214.32120795113
9: (303.7090048372623, -13.983407250062491) at t=61214.312342328754